Por Pablo Cerdeira
Não podemos abrir mão de nossa privacidade, mas também não podemos inviabilizar o uso de nossos dados pelos governos, do contrário não teremos a oferta de serviços públicos competitivos. Como equilibrar as duas faces dessa moeda?
Normalmente, quando se fala de dados e privacidade, os termos são colocados de forma antagônica. Se há uso de grandes volumes de dados, então há problemas com a privacidade. Mas, como em regra para quase todas as generalizações, isso não necessariamente é verdade. É possível termos um bom e racional uso de dados, mesmo grandes volumes de dados — o tão falado big data — e ao mesmo tempo favorecermos a produção de bens públicos e melhores serviços aos cidadãos, em especial por parte dos governos. Aliás, “possível” não é o melhor termo: é necessário usarmos grandes volumes de dados para termos melhores serviços.
Vamos dar uma olhada em dois cenários gerais e depois buscar o que, em nossa visão, parece ser o mais adequado.
De um lado ficamos a cada dia mais assustados com notícias de grandes coletas, capturas, usos indevidos ou até mesmo vazamentos de dados que podem comprometer nossa vida privada. É verdade, isso tem ocorrido em escalas nunca antes imaginadas. Veja-se o caso dos vazamentos de dados do Facebook por pesquisadores que, utilizados pela Cambridge Analytica — alegam estes — foram capazes de influenciar eleições pelo mundo todo. Veja-se o caso da China, que com seu sistema de identificação facial, com milhões de câmeras espalhadas por todas as grandes cidades, promete saber por onde passou cada habitante, a todo momento.
Diante desse cenário, é esperado, natural e desejável que a sociedade busque se proteger. E temos, como consequência, todas as leis de proteção de dados que surgem nos EUA, na Europa e até mesmo no Brasil. Não queremos um big brother governamental nos monitorando a todo momento.
Mas quais são as empresas mais valiosas do mundo atualmente? Amazon, Google (Alphabet), Apple, Facebook (com Instagram e WhatsApp) com certeza estão na lista. Não é curioso que as empresas mais promissoras para investidores sejam justamente as que mais dados coletam? Investidores, em geral, não gostam de perder dinheiro e, se estão investindo nessas empresas, é porque de alguma forma eles estão se saindo melhor do que a concorrência, ou até mesmo ocupando espaços que não imaginávamos existir.
E isso acontece porque essas empresas estão — com uso de muitos dados — conseguindo atender melhor a seus clientes e consumidores do que as que não usam. Vamos esquecer por alguns minutos eventuais violações de privacidade. Será que as pessoas de todo o mundo não estão preferindo — e se acostumando — a ter resultados customizados às suas buscas, ao invés de resultados genéricos? Será que não estão preferindo ler notícias que sejam compartilhadas por seus amigos, que compartilham interesses comuns, do que aquelas que aparecem em portais de notícias? Será que não estão se acostumando a ter recomendações de livros, músicas, filmes, séries e aplicativos que melhor atendam a seu perfil, ao invés de ver apenas os “campeões da semana”?
Por um lado, essas empresas estão derrotando suas concorrentes com essa estratégia. Mas por outro, entretanto, nossos governos estão ficando cada vez mais defasados quando comparamos seus serviços públicos aos dessas empresas. Imagine-se um cidadão que usa serviços altamente customizados, que já vêm moldados para suas demandas, tendo que solicitar um agendamento médico na rede pública de saúde. É preciso fazer cadastro em sites, enviar comprovantes, informar endereço, problema de saúde que está enfrentando… até que o governo informe que, como há muita demanda nos médicos daquele bairro, seu atendimento somente ocorrerá em 3 meses. Isso acontece para serviços médicos, mas também para educação, impostos, moradia, etc..
Isso é exatamente o oposto da experiência que essas empresas que usam muitos dados oferecem. Tome-se o exemplo da Uber. Um carro estará disponível para fazer o trajeto necessário. Pode ser que em determinados momentos o preço esteja mais alto, e o cliente prefira pegar outra modalidade. Pode ser que o cliente prefira um carro de luxo, pode ser que prefira economizar. O fato é que as opções são dadas, e muitas vezes pré-escolhidas, ou ao menos sugeridas, mas o serviço é muito mais simples, rápido e efetivo do que os serviços públicos.
Nesse cenário os governos passam a ser vistos como os vilões ineficientes. E, de fato, muitas vezes o são, mesmo. Veja quantos ônibus você encontrará circulando vazios em sua cidade, em especial nos horários noturnos. É claro que as pessoas que precisam de locomoção noturna precisam ser atendidas mas, colocar um veículo do tamanho de um ônibus, com capacidade para dezenas de passageiros, gastando combustível, pneu, emitindo poluentes, fazendo barulho, etc., apenas para atender a um pequeno grupo de pessoas não é a melhor opção. O mesmo vale para médicos, escolas e até mesmo habitação. Explicarei.
Nossa sociedade é, atualmente, muito mais dinâmica do que jamais o foi. E, mais do que isso, essa dinamicidade, que ocorre no nível individual e no nível social, encontra guarida nos serviços das empresas mais inovadoras citadas acima — mas não encontra no nível governamental. Imagine-se uma cidade que enfrenta, por exemplo, uma epidemia de dengue. Ela precisará de muitos médicos preparados para isso naquele ano, nos bairros mais afetados; mas, se a prefeitura abrir muitas vagas para epidemiologistas e realizar um concurso para preencher essas vagas, provavelmente no ano seguinte esses médicos estarão ociosos. Ao mesmo tempo, outra cidade poderá enfrentar um surto de dengue e não ter médicos para os atendimentos. O raciocínio serve também para demandas de outras naturezas, como educação. Talvez um bairro tenha grande demanda por professores de matemática em um ano, e outro bairro tenha para professores de português. E isso pode mudar nos anos seguintes.
A grande questão de fundo é: por um lado temos empresas com enorme capacidade de otimizar seus recursos (livros, resultados de buscas, carros, etc.) dominando o mercado. Por outro, temos governos arcaicos, que buscam a homogeneização de recursos. E a sociedade está claramente optando por aqueles em detrimento destes.
Como fazer, portanto, para que governos consigam ser tão efetivos quanto essas empresas, e assim melhor alocar os recursos públicos, ao mesmo tempo em que se preserva a privacidade?
Esse é um desafio posto, e ainda não completamente respondido. Mas temos algumas sugestões. No Rio de Janeiro liderei o primeiro Escritório de Inteligência de Dados de uma Prefeitura no hemisfério sul — o Big Data: PENSA — Sala de Ideias. Com uso de bilhões de registros anônimos, inclusive fornecidos por empresas privadas, como o Waze, fomos capazes de desenvolver projetos que ao mesmo tempo otimizavam recursos públicos e atendiam às demandas da sociedade.
Alguns exemplos: com cerca de 3 anos de dados, fizemos um relatório indicando quais as regiões com mais acidentes no Rio de Janeiro. Mas os dados não confirmavam os dados oficiais da cidade. E por uma razão simples: enquanto os dados oficiais representavam o número de acidentes, os dados gerados pelos usuários do Waze representavam a visão, a percepção da sociedade em relação aos acidentes. Claro, um acidente em uma via muito movimentada era reportado dezenas ou centenas de vezes pelo Waze, enquanto em uma via menos movimentada apenas algumas poucas vezes. Aparentemente os dados gerados pela sociedade conflitavam com os dados oficiais, mas na verdade os dados oficiais é que estavam em conflito com a percepção da sociedade em relação aos impactos.
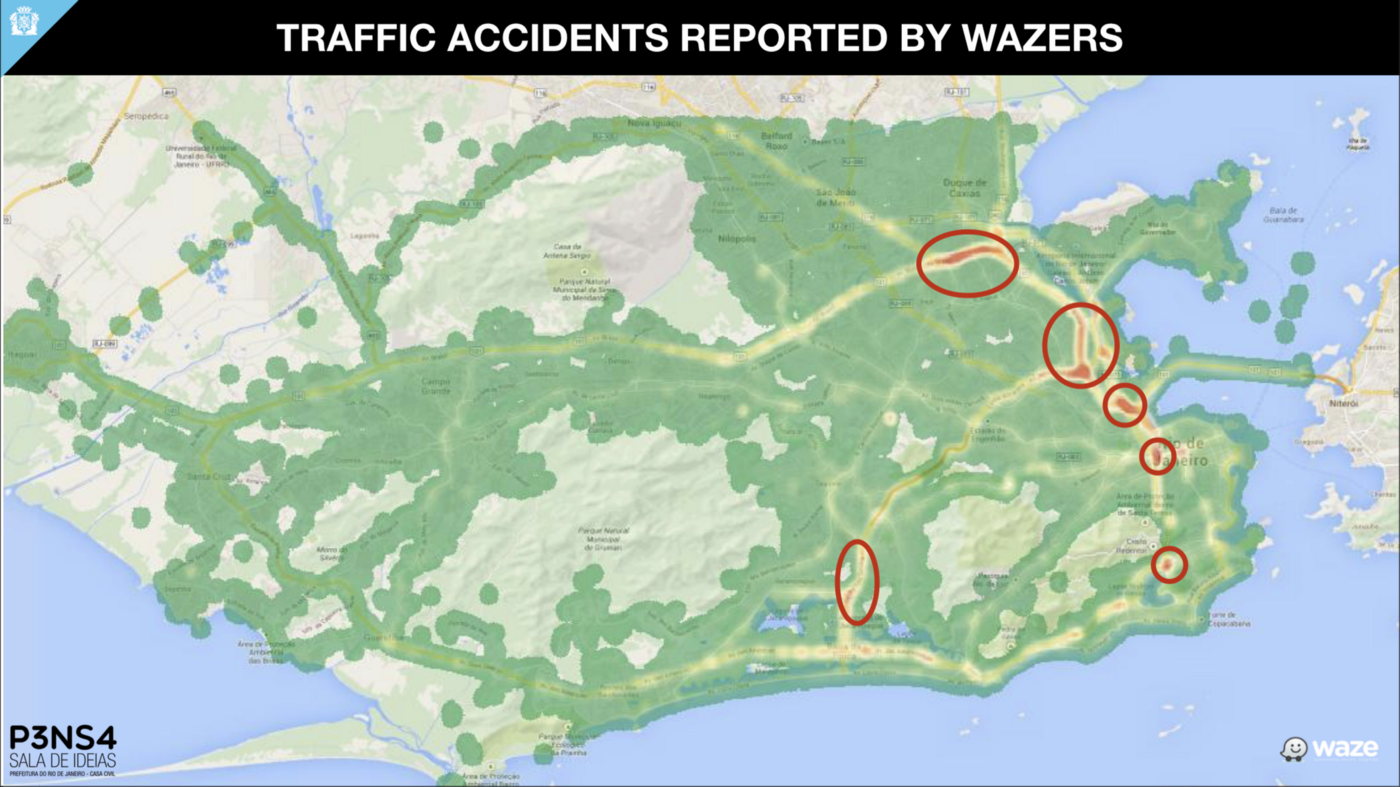
Estudos semelhantes, usando apenas dados anônimos, foram realizados para identificação de em quais bairros os casos de dengue surgiam antes dos demais; para sobreposição de linhas de ônibus e consequente otimização da frota; para redução do consumo de água e energia nas escolas; e até mesmo para identificar onde estava a população menos assistida por serviços públicos como transporte, praças etc.
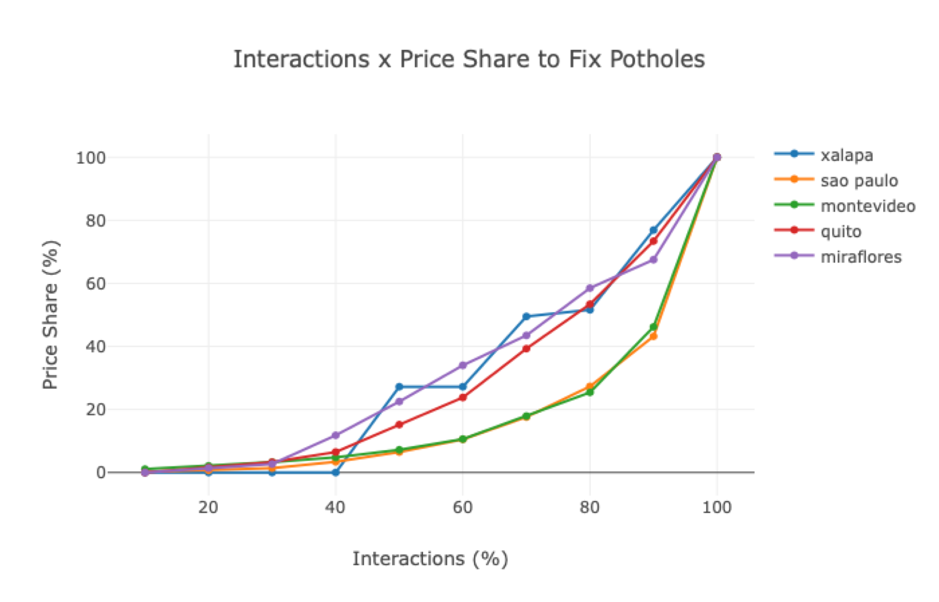
Agora, em parceria com o BID — Banco Interamericano de Desenvolvimento — e o Waze, estamos desenvolvendo métodos para melhor aplicar os recursos públicos para solução de problemas de pavimentação nas vias — ou os famosos buracos.
Analisando um enorme volume de dados de cinco cidades da América Latina conseguimos identificar que, em regra, 80% das reclamações de buracos se concentram em apenas 20% das áreas reclamadas. Essa distribuição 80%/20% é bastante conhecida na matemática como “regra de Pareto”. Isso quer dizer que se uma cidade precisa gastar 100 milhões de reais para corrigir todos os problemas de buracos, mas só tem 20 milhões de reais disponíveis em caixa, ainda assim ela poderá atender a 80% das reclamações da população.